

Pandasとは
今回は「 Pandas 」の基本的な使い方について紹介します 。
ディープラーニングでは様々なデータの集合体を扱います。その中で前回紹介した「Numpy」というモジュールは主に数値を行列のように扱い、計算や解析を行うことができます 。
→ 詳しくはこちら「初心者からはじめるディープラーニング入門! ~Numpy編~」
一方、本記事で紹介する「 Pandas」では数値以外の文字列などのデータを簡単に扱うことができる便利なモジュールになります。
Pandasの基本的な使い方
まずはPandasインポートおよび基本的な操作について説明します。
まずPandasモジュールを以下の方法で読み込みます。一般的にPandasはpdとして定義して扱います 。
import pandas as pdつぎにデータを読み込んでみましょう。ここでは一般に公開されているハウジングデータを読み込みます。
#データを読み込み
df = pd.read_csv('sample_data/california_housing_train.csv')
#ローカルに保存されているcsvファイルを読み込みたいとき
df = pd.read_csv('ここにファイルパスを与える')読み込んだデータを見てみましょう。ハウジングに関係のあるデータが列ごとに表示されていることがわかります。なおPandasで読み込んだデータをデータフレーム型として定義されます。
#GoogleColob上での出力を想定.
df出力結果
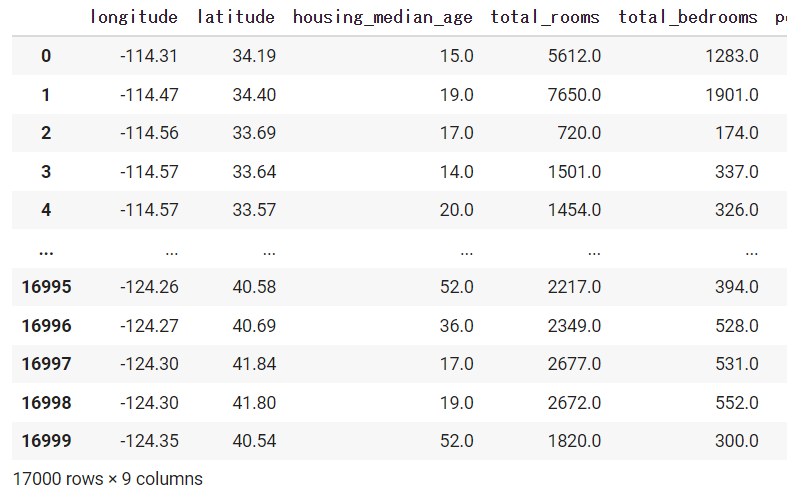
このようにcsvファイルなどを読み込みデータフレーム型して出力することができます!
データフレーム型の操作方法
では早速Pandasを用いてデータフレームを操作してみたいと思います!
データフレームから行・列を選択
まずデータフレームの中から任意の行・列を選択する方法について説明します。「.iloc」と記述することで要素を選択することができます。
# df.iloc[行, 列]
# 0 行目 longitude 列の選択
df.iloc[0, 0]出力結果 -114.31
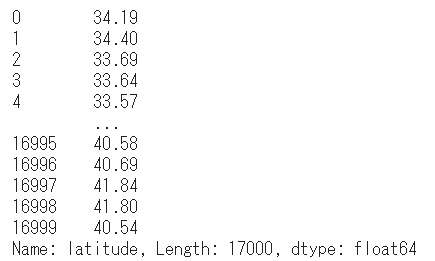
つぎに任意の行をすべて選択する方法です。「:」を引数に与えることで行をすべて選択することが可能です。
# すべての行の、1列目を選択
df.iloc[:, 1]出力結果
データフレームの任意の行を削除する方法
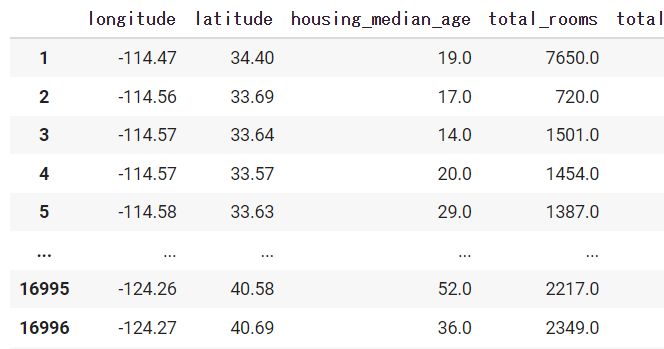
次にデータフレームの任意の行を削除する方法です。「.dorp」を使用して1行目のみ削除してみます。出力結果から1行目のデータが削除されていることがわかります。
# 1行目を選択
df.drop(range(0,1))出力結果
また要素名を指定して削除することもできます。1列目の「 longitude 」を引数に与えてみましょう.出力結果をみると「longitude」の列が削除されていることがわかります。
# longitudeを削除
df.drop("longitude",axis=1)このようにPandasを用いることでデータフレーム内の行・列の選択および削除を行うことができます!
Pandasを用いた統計量の確認
次にデータの統計量の確認方法について紹介します。ディープラーニングを行う上では重要な指標になりますのでぜひ参考にしてみてください!
Pandasを用いたデータフレームの統計量の確認方法についてみていきます。なおディープラーニングを実施するうえで統計量を事前に確認することは非常に重要になりますので覚えておいて損はありません!
ここでデータフレームの列ごとの平均値、最大値、最小値などの統計的情報をまとめたものを要約統計量といいます。「.describe」はデータフレームの列ごとの個数、平均値、標準偏差、最小値、四分位数、最大値などを返してくれます。なお得られたデータのインデックスは統計量の名前になります。
統計量の出力方法
さて実際に確認しましょう。出力結果より要約統計量が出力されていることがわかります。
# データの要約統計量
df.describe()
出力結果

任意の統計量を選択して出力
つぎに要約統計量中からの任意の統計量を選択してみましょう。選択する方法は、df.loc[“インデックスのリスト”]で行います。以下では平均値、最大値、最小値を選択します。
df.describe().loc[["mean","max","min"]]出力結果

Pandasを用いることでデータの要約統計量についても簡単に確認することができます。
データフレームの保存
最後にデータの保存方法についてです。Pandasではデータフレーム型をそのままcsvファイルとして保存することが可能です。
最後にデータフレーム型の保存について紹介します。データフレーム型の保存は「.to_csv」で行います。以下のコードは要約統計量を算出しCSVファイルに保存する方法になります。
#csvファイルに保存
df.describe().loc[["mean","max","min"]]
df.to_csv('describe.csv')まとめ
本記事では基本的なPandasの使用方法について紹介してきました。次回以降の記事ではディープラーニングに使用するデータに対するデータクレンジング手法などについて紹介したいと思います。

コメント