

こんにちは。Ganzy(ガンジー)です!今回は「 Pandas」 を用いたデータクレンジング手法について紹介していきます。
データクレンジングとは
データクレンジングとは、データを解析する際にエラー要因となるデータセット内の欠損値や不必要なデータに対して、補完・変換・削除することを処理のことを指してます。
このデータクレンジングはデータ解析前の必須事項であります。
Pandasを用いたデータクレンジング 欠損値
まず初めにPandasを用いて、データ内にある欠損値の扱い方について紹介していきます!
さてPandasを用いたデータクレンジング手法について説明します。
まずデータクレンジングを行う前に欠損値を含んだデータセットを作成します。出力結果を確認するとNAの個所が欠損値になります。
import numpy as np
from numpy import nan as NA
import pandas as pd
sample=pd.DataFrame(np.random.rand(5,3))
sample.iloc[1,0]=NA
sample.iloc[2,2]=NA
sample.iloc[4,1]=NA
sample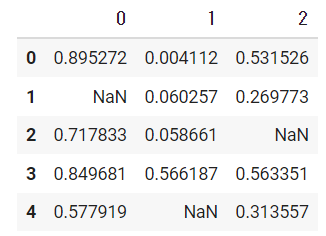
次にデータ内における欠損値の数を確認します。「.isnull.sum」を用いることで欠損値の数を確認できます。出力結果では各列ごとに欠損値が1つずつあるとカウントされてます。
#欠損値の数を表示
print(sample.isnull().sum())
欠損値のある行のみを選択して削除することも可能です。「.dropna()」で行うことができます。出力結果をみると欠損値のあった1、2、4行目が削除されていることがわかります。
#欠損値のある行を削除
sample.dropna()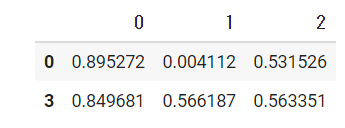
欠損値を補完することも可能です。「.fillna()」を用いて値を代入します。
以下のコードで任意の値、前の値、平均値を代入した例を示します。
なお個人的な感度では平均値を代入するのが一般的です。
#0を代入
a=sample.fillna(0)
a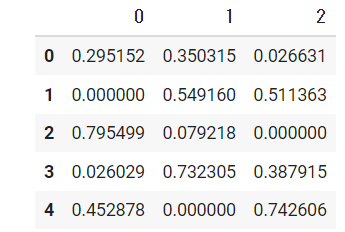
#前の値を代入
b=sample.fillna(method="ffill")
b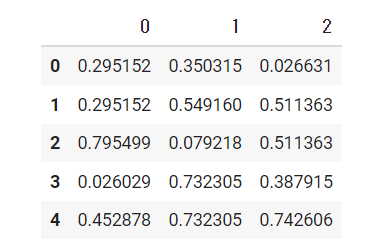
#平均値を代入
c=sample.fillna(sample.mean())
c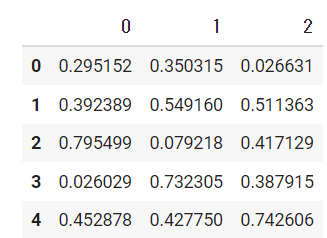
このようにデータ内にある欠損値の特定や補完などを行うことができます!データ解析を行う前は上記の操作を行うことがおすすめです!
デ ータクレンジング 不要データ削除
次に不要なデータの削除方法について紹介します。データの中にはしばしば重複しているデータなど不要なデータが存在してますので、これらも事前に確認することが重要になります。
不要なデータの削除方法について紹介します。ここで不要データを重複データとしてデータクレンジングを実施します。まず重複値のあるデータを作成します。
import numpy as np
from numpy import nan as NA
import pandas as pd
sample=pd.DataFrame(np.random.rand(5,2))
sample.iloc[1,0]=1
sample.iloc[1,1]=1
sample.iloc[2,0]=1
sample.iloc[2,1]=1
sample.iloc[4,0]=1
sample.iloc[4,1]=1
sample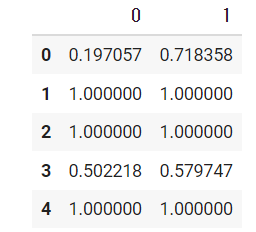
つぎに重複値を特定し削除を行います。「.duplicated()」を用いることで重複値を特定することができます。出力結果をみると1行目に重複している2行目、4行目に対してTRUEと返ってきているのがわかります。また重複値を削除したい場合は、 「drop_duplicates()」を用いることで重複値を削除することが可能です
#重複値を特定
sample.duplicated()
#重複値を削除
sample.drop_duplicates()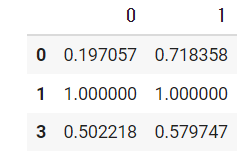
このようにPandasでは重複値の特定および削除を簡単に行うことができます!
まとめ
Pandasを用いたデータクレンジング手法について紹介しました。Pandasを用いることで、欠損値の補完・削除、重複値の削除が簡単に行うことができます。データクレンジングは機械学習・深層学習を行う上で必須事項になりますので是非参考にしてみてください。

コメント